The Pair Correlation Function
Derivation, overview, and guide to producing correlation functions from spatial data.
Author's Note
Unfortunately due to time constraints, this post is not fully fleshed out, it's missing crucial details. Nevertheless I have posted this in the hopes that at least this information may be of help.Introduction
The pair Correlation function \(g(r)\) is a metric on how the density of particles varies from a given distance \(r\) from a reference particle. When the particles you are observing can be approximated as radially symmetric, it is common to denote \(g(r)\) as the radial distribution function.
If we are given a volume \(V\) with \(N\) particles, we define the number density as
\[ \tag{1} \rho{} = \frac{N}{V} \]
In any given sample, we can expect the the average density of particles in an arbitrary sphereical shell of radius \(r\) to \(r+dr\) within the sample to be
\[ \rho{}g(r) \]
Of course in the case of an ideal gas, where particles do not interact with eachother and therefore have no variation in density (in other words meaning they are uniformly distributed) \(g(r) = 1\). Which is often used as a baseline for the function itself.
If we then assume
Derivation
As we previously have defined, we have a system of \(N\) particles in a volume \(V\). Our number density is defined in equation (1). If we assume some temperature in this system \(T\) of course we may define the Boltzmann constant as \(\beta{}=\frac{1}{kT}\). For those unfamiliar with statistical mechanics, you can think of this constant as a conversion factor between energy and temperature that will help us with determining the probability of a particle being in a given state. This, in essence, is the goal of statistical mechanics.
We can define the probability of a particle being in a state \(\psi_{i}\) (i.e. position, momenum, angular momentum) with energy \(E_{i}\) as:
\[ \tag{2} \mathbb{P}(\psi_{i}{}) = \frac{e^{-\beta{}E_{i}{}}}{Z} \]With the partition funciton \(Z\) defined as:
\[ Z = \sum_{i} e^{-\beta{}E_{i}{}} \]Similarly, if we were interested in particularly in interactions between particles, we could could concern ourselves with the interaction potential. The potential is what mediates the interaction between particles. We can isolate this equation to consider only potential energy \(U_{N}\) to only consider this form to concern ourselves only with the interaction between particles, often with respect to some distance parameter dependent on all other particles.
So, by denoting the set of distances within a given sample \( \{ \mathbf{r}_{1}, ... ,\mathbf{r}_{N} \}\), in which case we have made them vectors. And defining our potential for each particle with respect to these distances \(U_{N}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N})\). We can define the probability of a set of particles being at any given set of positions as:
\[ \tag{3} \mathbb{P}^{[N]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N}) = \frac{e^{-\beta{}U_{N}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N})}}{Z_{N}} \]With the partition funciton \(Z\) defined as:
\[ Z_{N} = \int{}...\int{} e^{-\beta{}U_{N}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N})} d\mathbf{r}_{1} ... d\mathbf{r}_{N} \]As you might note, the set of states is continuous, so we must integrate over all possible states. As opposed to the partition function in equation (2) where we assume the set of energies in this case to be discrete. As another note, this is likely difficult, if not impossible to calculate in practice.
With this in mind, let's make this computation easier by fixing the positions of the first \(n\) particles. This is a common assumption in statistical mechanics, and is known as the fixed particle approximation. This allows us to simplify our calculations by reducing the number of variables we need to integrate over. Our probability then becomes.
\[ \tag{4} \mathbb{P}^{[n]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{n}) = \frac{1}{Z_{N}}\int{}e^{-\beta{}U_{N}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N})} d\mathbf{r}_{n+1} ... d\mathbf{r}_{N} \] \[ = \frac{e^{-\beta{}U_{N}(\mathbf{r}_{1}, ... ,\mathbf{r}_{n})}}{Z_{N}}\int{}e^{-\beta{}U_{N}(\mathbf{r}_{n+1}, ... ,\mathbf{r}_{N})} d\mathbf{r}_{n+1} ... d\mathbf{r}_{N} \]If this step is still confusing (as it was for me). If we're only interested interested in any two particles, and the positions between them, we can say what is the probability that they will be at two fixed positions (i.e. a given distance away from one another) will be given by the function:
\[ \mathbb{P}^{[2]}(\mathbf{r}_{1},\mathbf{r}_{2}) = \frac{e^{-\beta{}U_{N}(\mathbf{r}_{1}, \mathbf{r}_{2})}}{Z_{N}}\int{}e^{-\beta{}U_{N}(\mathbf{r}_{3}, ... ,\mathbf{r}_{N})} d\mathbf{r}_{3} ... d\mathbf{r}_{N} \]You can interpret this equation as describing the ratio two fixed particles being at given positions \( \mathbf{r}_{1}\) and \(\mathbf{r}_{2} \) over all positions of \( \mathbf{r}_{1}\) and \(\mathbf{r}_{2} \). This in essence is what the pair correlation function looks to calculate.
So why don't we use it?
Exactly, as I had thought. This is what is known as the 2-Particle Probability Distribution Function and while it is quite useful in its own right, it describes the system in terms of absolute positions. This is not easy to measure, especially in something like a fluid or a gas. So something like the relative distances between particles is something that would be more useful to us, and tell us about the system.
Our next step in defining this radial distribution function, is to define the particle density.
This can be quite unintuitive, as the definiton of the N-Particle-Density looks very similar to the N-Particle Probability Distribution Function. The best way to begin to look at this is to consider the simplest case.
\[ \mathbb{P}(r) = \frac{1}{V} \hspace{15px} and, \hspace{15px} \rho{} = \frac{N}{V} \hspace{15px} therefore, \hspace{15px} N\mathbb{P}(r) = \rho{} \]In the case that the particles do not interact, and are perfectly uniform. You can see that the probability is based on the volume of the circular sample. Where the density is based on the number of particles in the volume.
When we scale this back up to finding the set of particle positions to be in a given configuration yielding density \(\rho{}^{[N]}\), we can see that the probability of a set of particles being:
\[ \rho^{[N]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N}) = N!\mathbb{P}^{[N]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{N}) \]Once again, calculating this is difficult, so we can use the fixed particle approximation to simplify this to:
\[ \tag{5} \rho^{[n]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{n}) = \frac{N!}{(N-n)!}\mathbb{P}^{[n]}(\mathbf{r}_{1}, ... ,\mathbf{r}_{n}) \]The purpose of using a factorial lies in the fact that the variable positions of each \(N\) particles can commute, and swap places with any of the other \(N\) different positions to obtain the same density, and therefore needs factored into the equation. Once we fix the first n particles, their positions become definite and the factorial is no longer needed for them since they are fixed in place.
Technical Notes
This function obfuscates a lot of the statistical mechanics embedded in it. Meaning if you'd wanted to calculate \(g(r)\) yourself. Your first step would be to calculate the pair correlation function from a sample, even in the simplest case of an ideal gas you would likely get something that looked like:
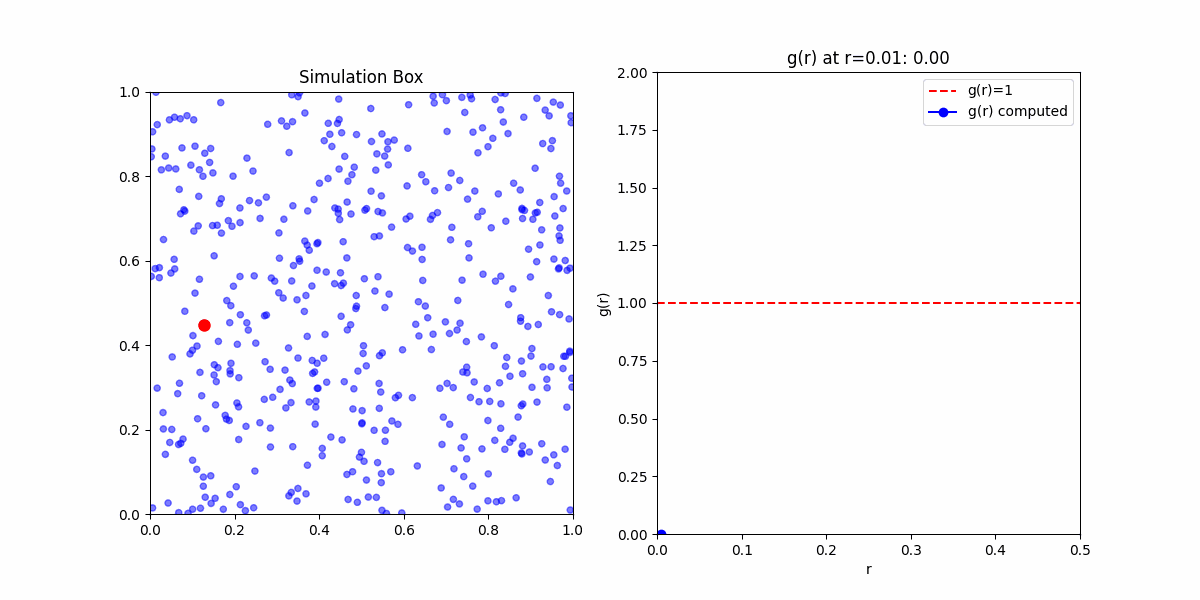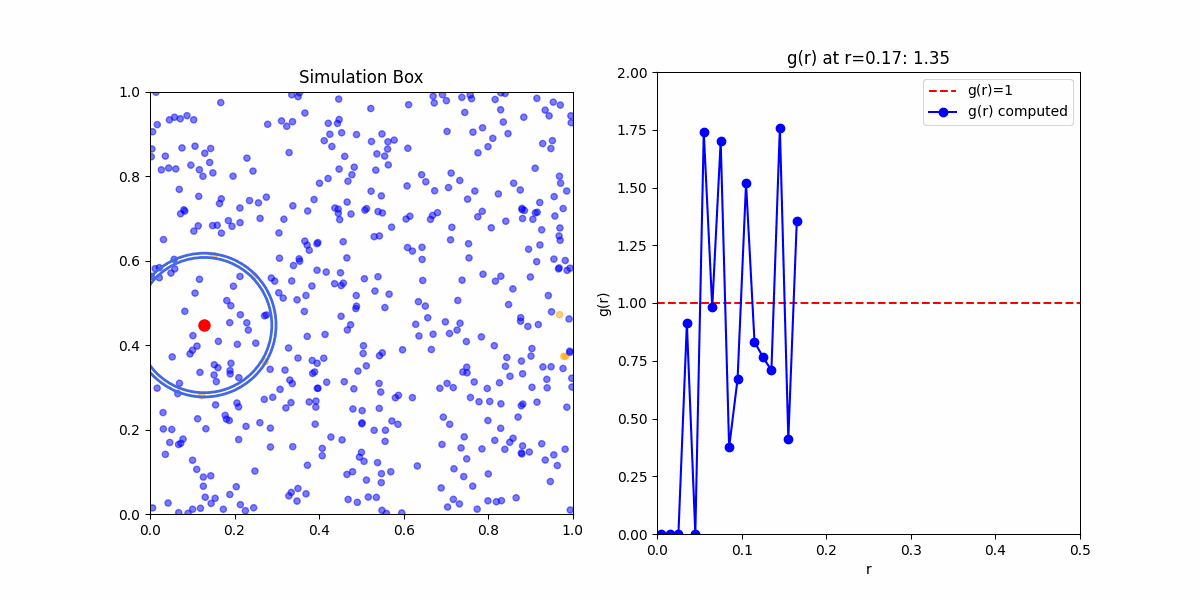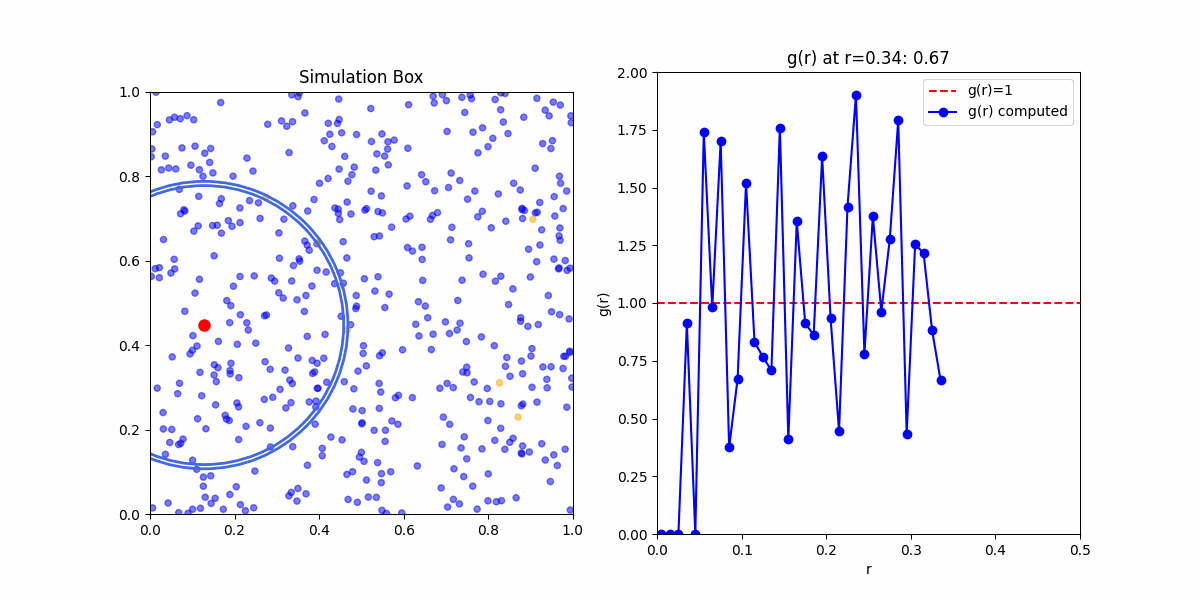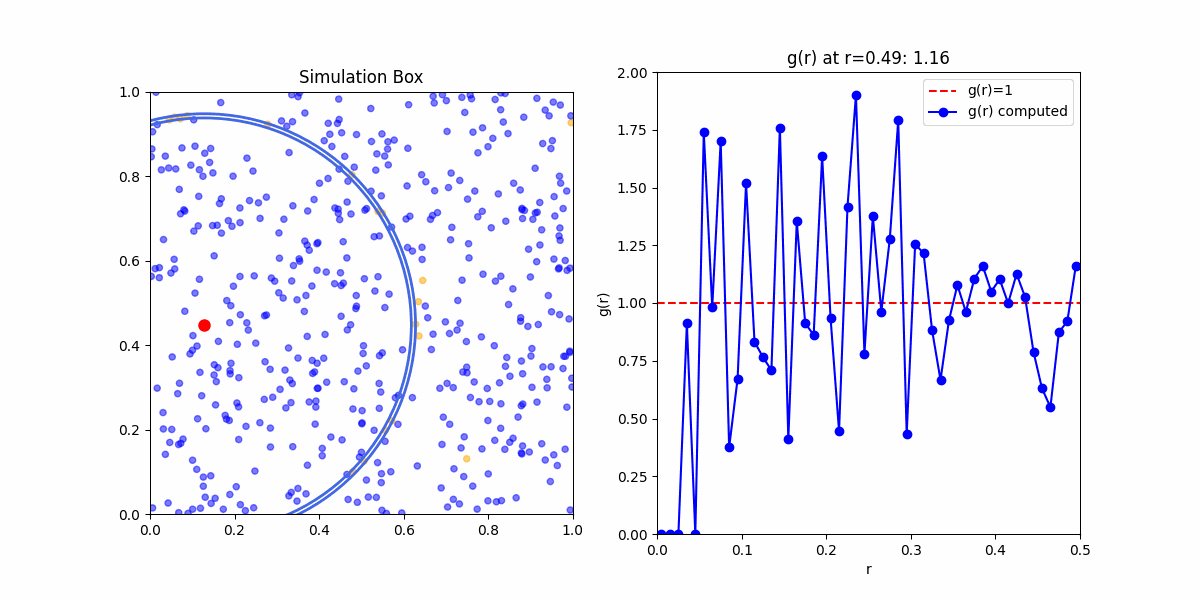
This is because the pair corelation is an ensemble average of densities of particles at a given distance from a reference particle. To get meaningful results, we need to take the average of the pair correlation function over many samples.
There are two ways we can do so:
Microstate Average - The average over the reference particles in a single sample.
Ensemble Average - The average over various samples of possible states in the system.
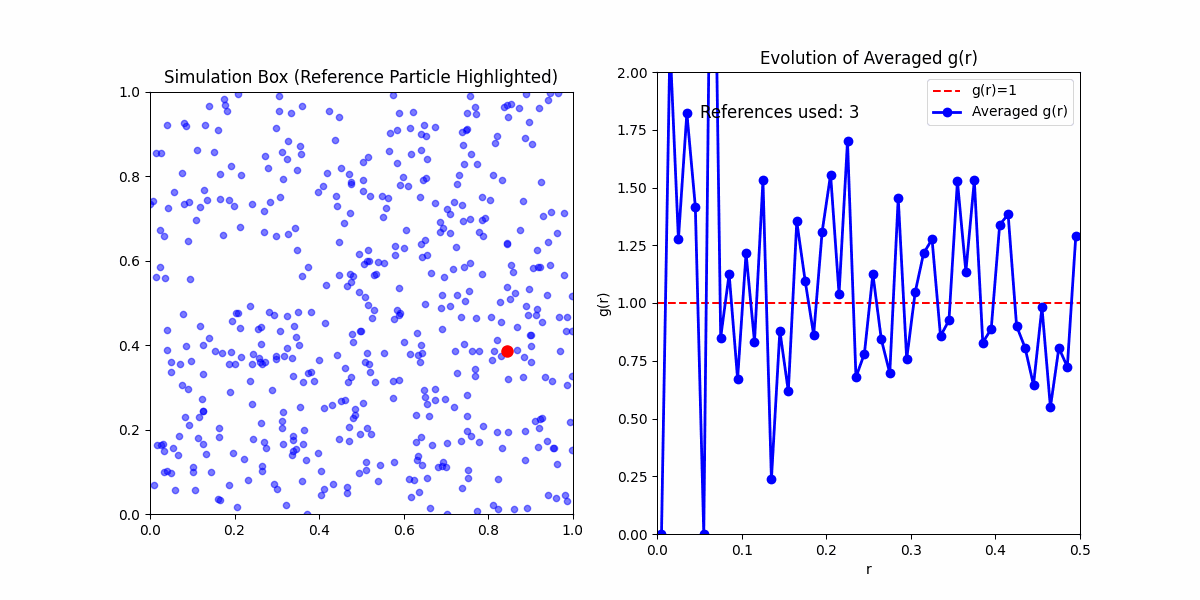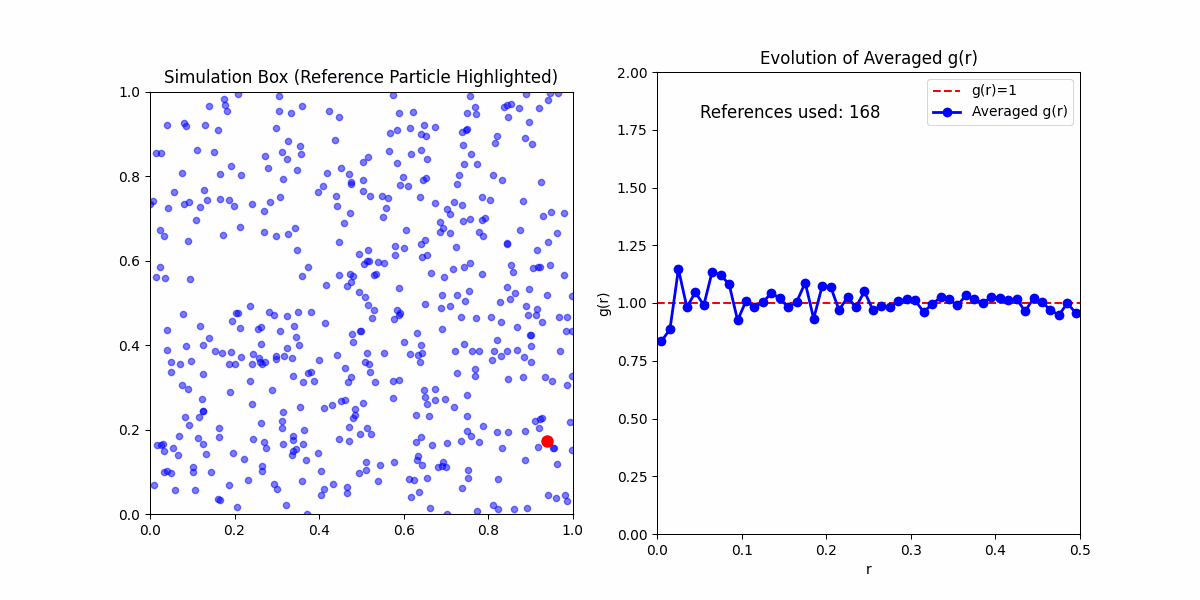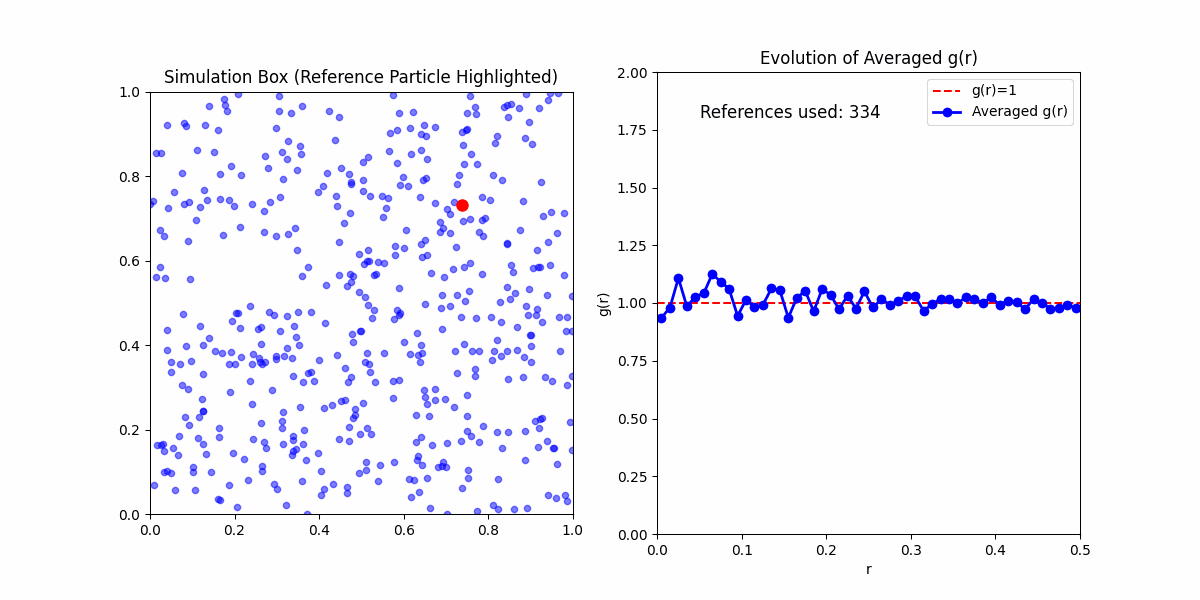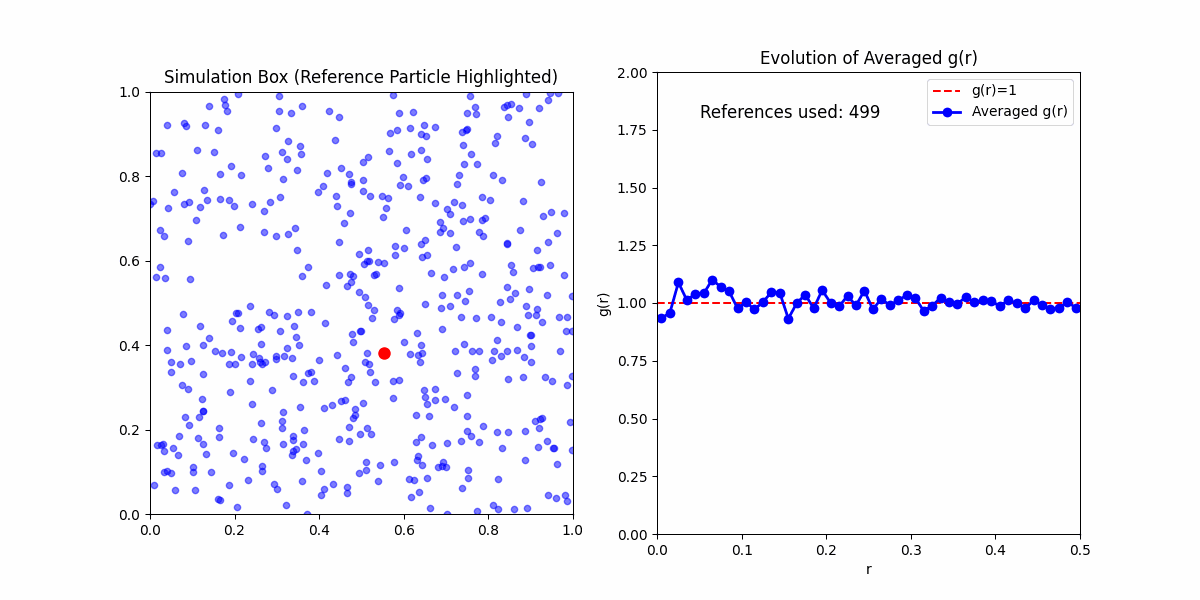
Here, we will mainly concern ourselves with the microstate average, since we are only concerned with the pair correlation function of a single sample. Expections are otherwise clarified.
One final thing to note about running simulations for a given pair correlation function. Any boundry method that isn't periodic will introduce artifacts to some degree. It may increase in the amount of randomness at high radii, as well as introduce a positive/negative bias in the pair correlation function.
- Wikipedia (n.d.). Radial Distribution Function.